
使用java进行网络爬虫需要以下先决条件:jdk安装、html/xml知识和网络协议理解。java提供了jsoup(html解析)、httpclient(http请求)和selenium(浏览器自动化)等库和框架。编写网络爬虫涉及以下步骤:...
使用java进行网络爬虫需要以下先决条件:jdk安装、html/xml知识和网络协议理解。java提供了jsoup(html解析)、httpclient(http请求)和selenium(浏览器自动化)等库和框架。编写网络爬虫涉及以下步骤:发送http请求获取网页内容,解析html/xml提取数据,遍历链接抓取更多网页,存储数据并处理异常。示例代码使用jsoup从网页中提取文本内容。

Java爬虫指南
在当今数字时代,网络爬虫已成为信息收集和分析的宝贵工具。Java作为一种强大的编程语言,提供了丰富的网络爬虫功能。本文将指导你如何使用Java编写网络爬虫。
入门:
使用Java进行网络爬虫需要以下先决条件:
安装Java开发工具包(JDK) 熟悉HTML和XML 了解网络协议(HTTP、HTTPS)库和框架:
Java提供了一些库和框架,简化了网络爬虫的开发,包括:
Jsoup:一个用于解析HTML的库 HttpClient:一个用于发送HTTP请求的客户端 Selenium:一个用于自动化浏览器交互的框架编写网络爬虫:
编写Java网络爬虫需要几个关键步骤:
1. 发送HTTP请求:
使用HttpClient发送HTTP GET或POST请求获取网页内容。 从响应中提取HTML或XML文档。2. 解析HTML/XML:
使用Jsoup或其他解析库解析HTML或XML文档。 提取所需的数据,例如文本、链接和图像。3. 遍历链接:
从解析的文档中提取链接。 使用递归或迭代遍历链接,以抓取更多网页。4. 存储数据:
将提取的数据存储在数据库、文本文件或其他存储介质中。5. 处理异常:
处理网络错误、解析错误和文件写入错误等异常情况。示例代码:
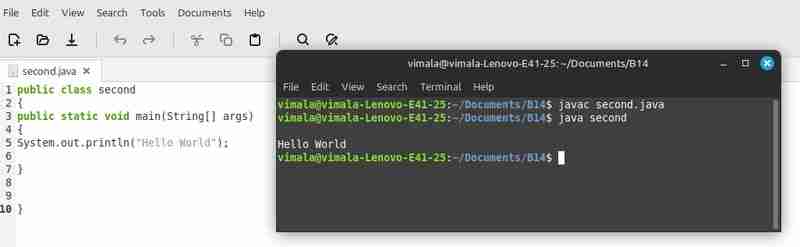
以下是一个使用Java爬取网页文本内容的示例代码:
import org.jsoup.Jsoup; import org.jsoup.nodes.Document; public class SimpleCrawler { public static void main(String[] args) { String url = "https://example.com"; try { Document doc = Jsoup.connect(url).get(); String text = doc.text(); System.out.println(text); } catch (IOException e) { e.printStackTrace(); } } }结论:
通过遵循这些步骤并利用Java库和框架,你可以轻松创建功能强大且高效的网络爬虫。网络爬虫在数据收集、搜索引擎优化和竞争情报等领域有着广泛的应用。
以上就是java怎么爬虫的详细内容,更多请关注知识资源分享宝库其它相关文章!
版权声明
本站内容来源于互联网搬运,
仅限用于小范围内传播学习,请在下载后24小时内删除,
如果有侵权内容、不妥之处,请第一时间联系我们删除。敬请谅解!
E-mail:dpw1001@163.com
上一篇:java的多态怎么写 下一篇:c语言中ln函数怎么表示










发表评论