
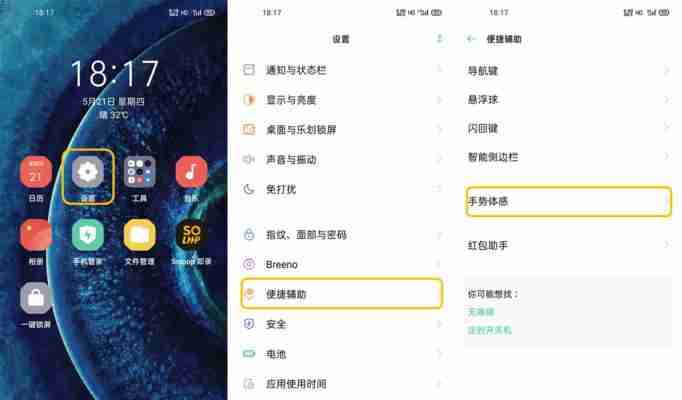
oppo 手机可以通过以下步骤截取长截图:1. 截取初始截图,2. 选择滚动截图选项,3. 滚动屏幕并截取,4. 停止截取,5. 编辑和保存您的长截图。
如何在 OPPO 手机上截取长截图
OPPO 手机提供了一种便捷的方法来截取长截图,...
oppo 手机可以通过以下步骤截取长截图:1. 截取初始截图,2. 选择滚动截图选项,3. 滚动屏幕并截取,4. 停止截取,5. 编辑和保存您的长截图。

如何在 OPPO 手机上截取长截图
OPPO 手机提供了一种便捷的方法来截取长截图,方便您轻松捕获屏幕上的所有内容,而不仅仅是当前可见的部分。以下是如何操作:
步骤 1:截取初始截图
- 按住电源键和音量降低键同时截取常规截图。
步骤 2:选择滚动截图
- 截取屏幕截图后,您将在屏幕底部看到一个“滚动截图”选项。点击它。
步骤 3:滚动屏幕并截取
- 在滚动截图模式下,您可以向下滚动网页或应用程序,而 OPPO 手机将自动捕获屏幕上的其余部分。
- 滚动到要截取的区域的底部。
步骤 4:停止截取
- 滚动到底部后,点击屏幕上的“完成”按钮停止截取。
步骤 5:编辑和保存
- 您的长截图将自动保存在您的相册中。您可以在相册中对其进行编辑,调整大小或将其另存为 PDF 文件。
以上就是oppo手机怎么截短图的详细内容,更多请关注知识资源分享宝库其它相关文章!
版权声明
本站内容来源于互联网搬运,
仅限用于小范围内传播学习,请在下载后24小时内删除,
如果有侵权内容、不妥之处,请第一时间联系我们删除。敬请谅解!
E-mail:dpw1001@163.com
上一篇:oppo手机怎么清理空间 下一篇:oppo手机怎么投屏到投影仪上






发表评论